A roadmap your agent reads
Set milestones, define specs, and the agent pulls what's next from your plan — not its own guess. Blocked work drops out of the queue. You see progress in real time.
Sync is the project-management and quality-control layer your AI agents work against. Define your specs, rules, decisions, and roadmap once — Sync holds every agent accountable to them, so they build against your architecture instead of hallucinating or repeating past mistakes. When the code moves, stale context gets flagged and the agent has to stop and ask.
From install to results in one step. Runs entirely on your machine — nothing is ever uploaded. Currently in alpha · v0.6.13. Building team & cloud features — join the waitlist.
MCP server · Desktop app · Built-in terminal · Claude Code · Cursor · Zed · Codex · OpenCode
An agent is only as aligned as what it reads. Point it at stale, scattered context on a large task and it heads off course — confidently, while you're looking the other way.
It trusts whatever it finds, even when the code moved on months ago.
Where docs are missing, it invents plausible-but-wrong context.
It re-litigates choices you already overturned, again and again.
Get started in seconds
No mandatory terminal commands, no git clone, no long configuration files. Everything happens in the desktop app or with a single click.
Download Sync for macOS, Windows, or Linux. One binary, no dependencies — just open it.
Point Sync at any local repository. It sets up the .sync/ knowledge base automatically — no manual config.
The Welcome wizard wires up Claude Code, Cursor, Zed, Codex, or OpenCode instantly — and you can run them right inside Sync's built-in terminal. No config files.
Latest release v0.6.13 · macOS, Windows & Linux · free and open source
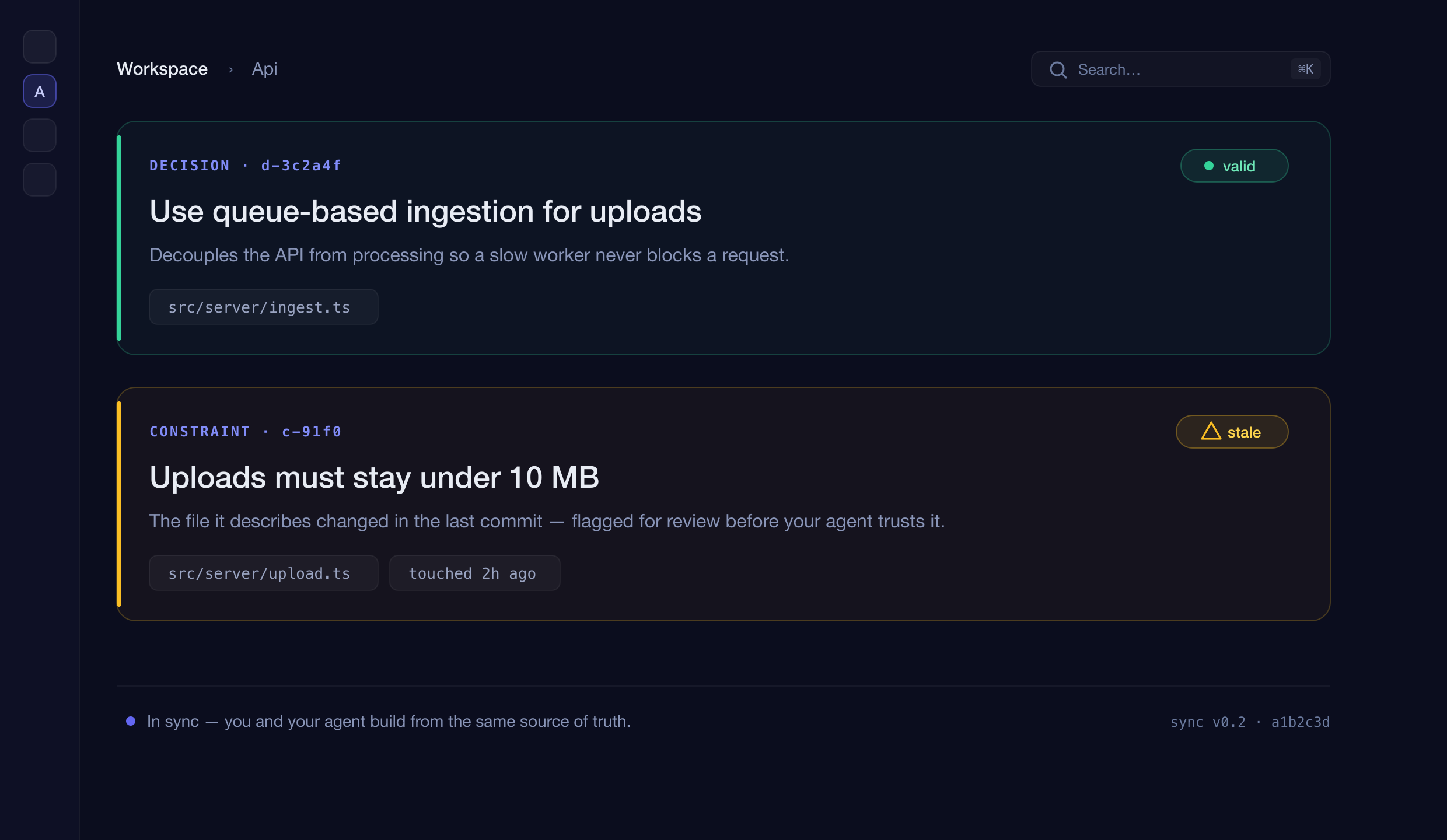
Decouples the API from processing so a slow worker never blocks a request. Supersedes the inline approach.
The file it describes changed in the last commit — Sync flags it for review before your agent trusts it.
How Sync is different
AI coding agents are powerful, but without a plan to work against they cause architectural drift, forgotten decisions, and regressions. Memory files and wikis can hold context — they aren't built to keep an agent accountable to your project. Sync is: a mission-control layer above your editor and agent.
Sync Project management & quality control | Memory systems e.g. Cursor rules | Documentation Confluence · Notion | |
|---|---|---|---|
| Primary goal | Control agent results & enforce quality | Provide simple text context to the agent | Human-readable knowledge sharing |
| Structure | Strict, agent-readable constraints & widgets | Free-form text files | Unstructured text, tables, images |
| Staleness tracking | Automatic — tied tightly to code changes | None / manual | Manual audits required |
| Agent behavior | Must respect the rules; asks for approval when context goes stale | Reads notes, but often ignores them | Usually can't access it seamlessly |
| User experience | Visual Project Hub, widgets, direct oversight | Simple text editing | External web interface |
Sync works as a highly effective memory system too — but its real power is governance and quality control.
Why Sync
Structured, versioned, and always current — so you and your agent (and the whole team) build the same thing, instead of you cleaning up after it drifts.
Automated quality gates
Every entry is bound to the code it describes. When a commit moves past it, Sync marks it stale — pointing at the exact commit and files — and makes the agent stop and ask for your input instead of silently building on old data.
Sessions are signed JWTs with a 15-minute expiry.
scope · src/auth/session.ts
Written as it works
Specs, decisions, constraints, and observations get captured during coding, by the agent, in typed structure it can query precisely later — not prose nobody re-reads.
Use refresh-token rotation on every renew.
Never log raw tokens or PII — redact at the boundary.
Project Hub — roadmap, specs, milestones
Goals → milestones → specs, used not as notes but as control elements. This is the plan you point the agent at — it pulls what's next from your roadmap and codes against it, instead of its own guess.
The most important part of big work
The hard part of a large task isn't typing the code — it's keeping the work pointed at the right outcome. Sync makes the agent's direction legible and steerable.
You decide; it proceeds. Nothing auto-commits.
Run agents where you steer them
Launch your agents right inside Sync — multiple terminals side by side, each opened into your project and wired to its context through the built-in MCP server. No separate console window, no context switching.
From you to the whole team
You start alone on the hard problem. Because the knowledge lives in git, it stops being your private context the moment you push — the whole team and their agents read and steer with the same fresh plan.
decision · d-3c2a4f — Token strategy
One developer writes it. The whole team — and their agents — read and steer with it.
Project Hub & Widgets
Not just notes — a task tracker agents actually work against, with a visual dashboard that shows exactly what's happening in your project right now.
Set milestones, define specs, and the agent pulls what's next from your plan — not its own guess. Blocked work drops out of the queue. You see progress in real time.
Add widgets to visualize project health, open questions, stale entries, or any metric. Your agent can create dashboards too — turning Sync into a living operations console.
And more
Every entry is valid, unverified, stale, or invalid — so neither you nor your agent ever builds on context that quietly went wrong.
Choose the language your agent writes docs in. Ready-made presets, plus any BCP-47 tag — so specs, decisions, and docs read naturally for your team.
Typed links — depends_on, supersedes, references — built from frontmatter, manual links, and body mentions.
Discussion pinned to exact text. A human answer becomes the canonical, attributed part of the spec.
Switch between projects from the side rail, or group several into a curated workspace and steer them as one.
Every entry is bound to the files it describes. When the code changes, Sync re-checks the affected knowledge and flags what drifted — no manual audits.
Built-in quality gates
Projects change. Files move. APIs get renamed. Left unchecked, your agent keeps trusting context that quietly went stale — and it won't tell you. Sync's staleness engine ensures it has to.
When a commit touches files a spec or decision describes, Sync marks it stale — pointing at the exact commit and drifted files. No manual audit.
Instead of silently building on old data, the agent has to surface what went stale and ask you to re-validate it — shutting down the #1 hallucination path.
Nothing is auto-committed. You review the agent's proposed decisions and answer its questions in the Project Hub — you're always in the driver's seat.
Who is it for
Whether you're building solo or leading a team, Sync makes your relationship with agents predictable — and keeps you in charge.
Delegate routine to agents, keep the architect role. Set the direction once — the agent builds against your plan, not its guess.
Stop repeating instructions to your agent. Write a spec once, link it to the code, and every session gets the canonical version — reasoning included.
Write specs the AI actually reads and executes — not prose that dies in Notion. Link acceptance criteria to milestones. Watch progress happen.
And not just software. Because your agent authors custom widgets, the Project Hub adapts to whatever you're building:
Sync is free and open source today. We're building team and cloud features next — drop your email and we'll tell you first. No noise in between.
FAQ
Sync is the project-management and quality-control layer your AI agents work against. You define the project — its specs, rules, decisions, and roadmap — and Sync holds every agent accountable to it, so they follow your architecture and constraints instead of hallucinating or repeating past mistakes. Everything lives in your repository; there is no cloud, no account, and no telemetry.
Wikis and Markdown rot silently: nothing tells you when a page no longer matches the code, and your agent usually can't access them seamlessly anyway. Sync stores structured, agent-readable specs and constraints, ties each one to the files it describes, and flags it stale when those files change — so the agent never pattern-matches against out-of-date information.
You can use Sync as a highly effective memory system — but that's not the point. Memory tools pass raw text to the agent and hope it's still true. Sync's job is governance: it ties every spec, decision, and constraint to the code it describes, makes the agent respect them, flags them stale when the code changes, and forces it to stop and ask for your approval before acting on old data. The power is control and quality, not just recall.
You set the plan the agent works against — goals, milestones, and specs ranked by priority. As it works, the agent reads your constraints, updates the roadmap, and files open questions when it hits ambiguity; your answers become canonical. You overturn decisions and set constraints it must respect. Nothing is auto-committed — you review and approve every change. You steer the direction; the agent follows.
In your repository. Sync writes plain files under `.sync/` — there is no SaaS backend, no account, and nothing is uploaded. Your knowledge is versioned, reviewable in pull requests, and travels with the code.
Any MCP-capable client. The Welcome wizard wires up Claude Code, Cursor, Zed, OpenCode, and Codex for you instantly — and you can run them right inside Sync's built-in terminal. For anything else, point your client at the binary with `claude mcp add git-sync -- git-sync mcp`. Sync ships as a desktop app and a CLI, and the binary itself is the MCP server.
Sync is currently in alpha. It's usable today and improving fast, but the internal data model can still change between releases. Hit a rough edge? Open an issue on GitHub — issues and pull requests are warmly welcome.
Sync is free and open source under the Functional Source License (FSL-1.1-MIT), which reverts to MIT two years after each release — free for all non-competing use. It runs entirely on your machine. Paid team and cloud features are coming later — join the waitlist to be first in line.
Sync is free and open source. Nothing is uploaded — everything lives in your repo, on your machine. Your agent works from reviewed context that matches your architecture, and you approve every change.